
Test des 5 meilleurs scrapers Google Maps (prix / performance)
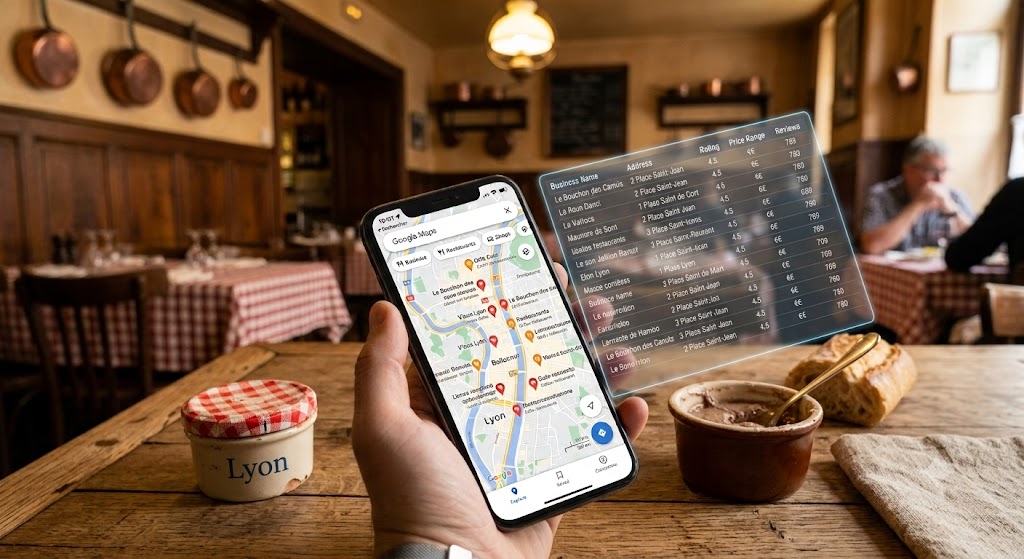
Savez-vous ce qui lie la tech de pointe et tradition culinaire lyonnaise ? Absolument rien. Et c'est exactement pour ça qu'on adore le scraping. Pour notre grand comparatif des outils d'extraction de données sur Google Maps, j'ai décidé de bouder les éternels salons de coiffure et agences immobilières. À la place, on s'attaque à un monument : le bouchon lyonnais. Derrière ce nom rigolo se cachent les restaurants historiques de Lyon, réputés pour leur ambiance unique et leurs plats... disons, très riches en lipides. Alors, quel est le meilleur outil pour récupérer les données Google Maps de ces pépites locales sans se faire bloquer par les anti-bots de Google ? Enfilez votre plus beau tablier, on passe au grill les solutions du marché. Nous allons scraper tous les bouchons qui se trouvent dans la capitale des Gaules avec cette recherche. Notre recherche étant de petite taille et sur un périmètre géographique limité nous évaluerons les performances des plateformes de scraping selon leurs offres de base.
1. OpenScraper.ai
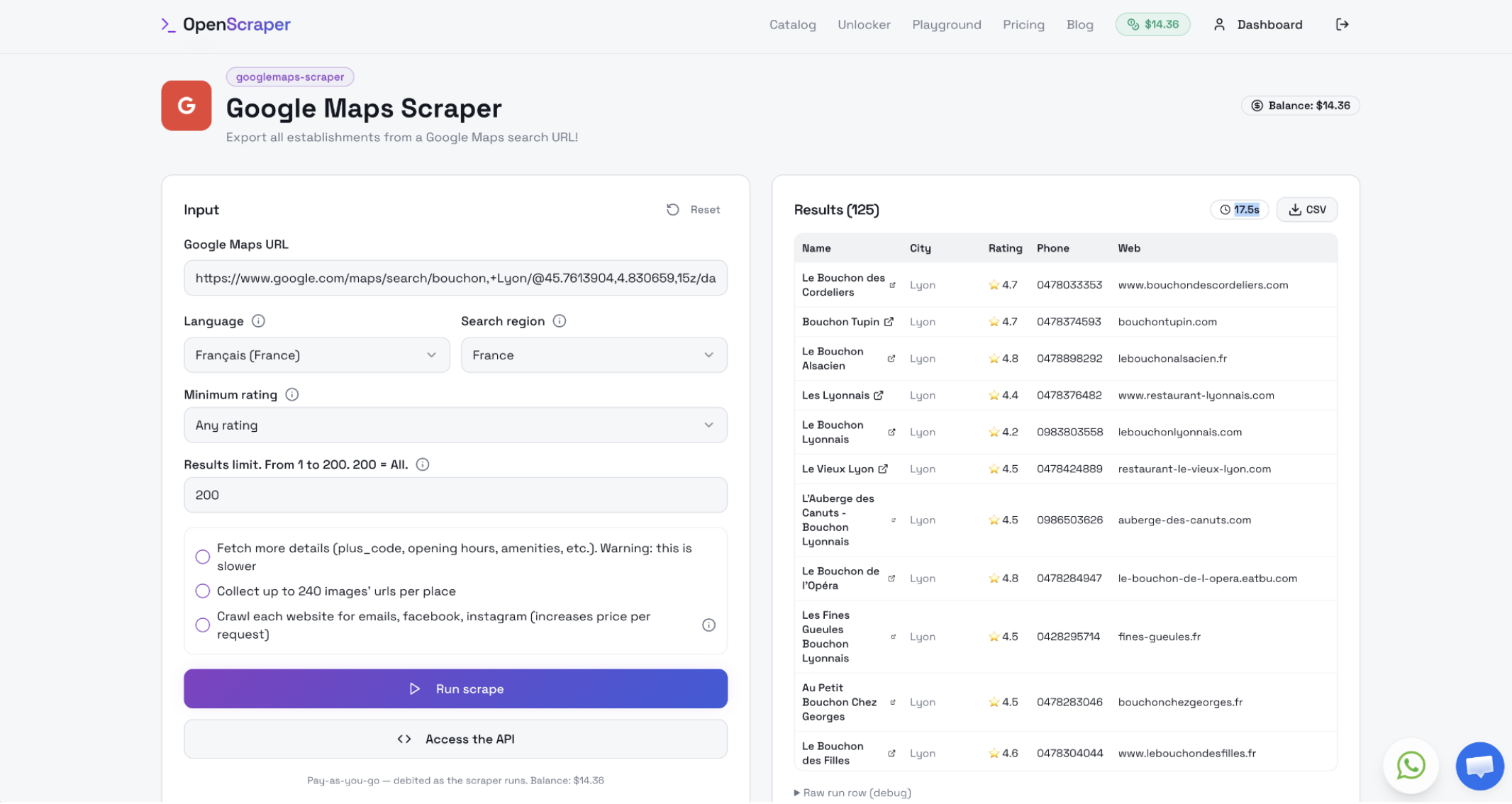
Et le grand gagnant de notre crash-test est… Openscraper ! Cocorico, c’est une solution française qui monte sur la plus haute marche du podium 🇫🇷.
Si vous cherchez le meilleur rapport qualité-prix pour remplir votre base de données sans vider votre portefeuille, ne cherchez pas plus loin : l'outil nous a sorti un tarif imbattable, ultra-compétitif de 0,00112 $ par ligne extraite (on est passé de 14,36 $ à 14,22 $ de crédits pour notre test, autant dire des clopinettes). Non seulement leur offre en Pay-as-you-go est ultra-flexible (vous n'avez pas besoin d'abonnement), mais le scraper a avalé les serveurs de Google en seulement 17,5 secondes chrono soit la deuxième meilleure perf du benchmark.
Travail carré : récupération de l'intégralité des 125 résultats attendus sans aucune ligne manquante.
Alors oui, l’interface SaaS est moins exhaustive que d’autres en termes de paramètre et très "API-first", mais il suffit de générer un petit script pour qu’elle fasse des merveilles. Ce qui est très facile avec ChatGPT.
Je vous donne le script que j'ai utilisé pour le test et qui enregistre les résultats en CSV. Veillez juste à remplacer "YOUR_API_KEY" par votre clé API !
On appréciera :
• Un tarif imbattable, ultra-compétitif de 0,00112 $ par ligne
• Deuxième solution la plus rapide du marché ⚡
• Une solution française 🇫🇷
• Les données récoltées sont complètes 🌾🚜
On aime moins :
• Plus optimisé en API qu'en 100 % SaaS.
2. APIfy :
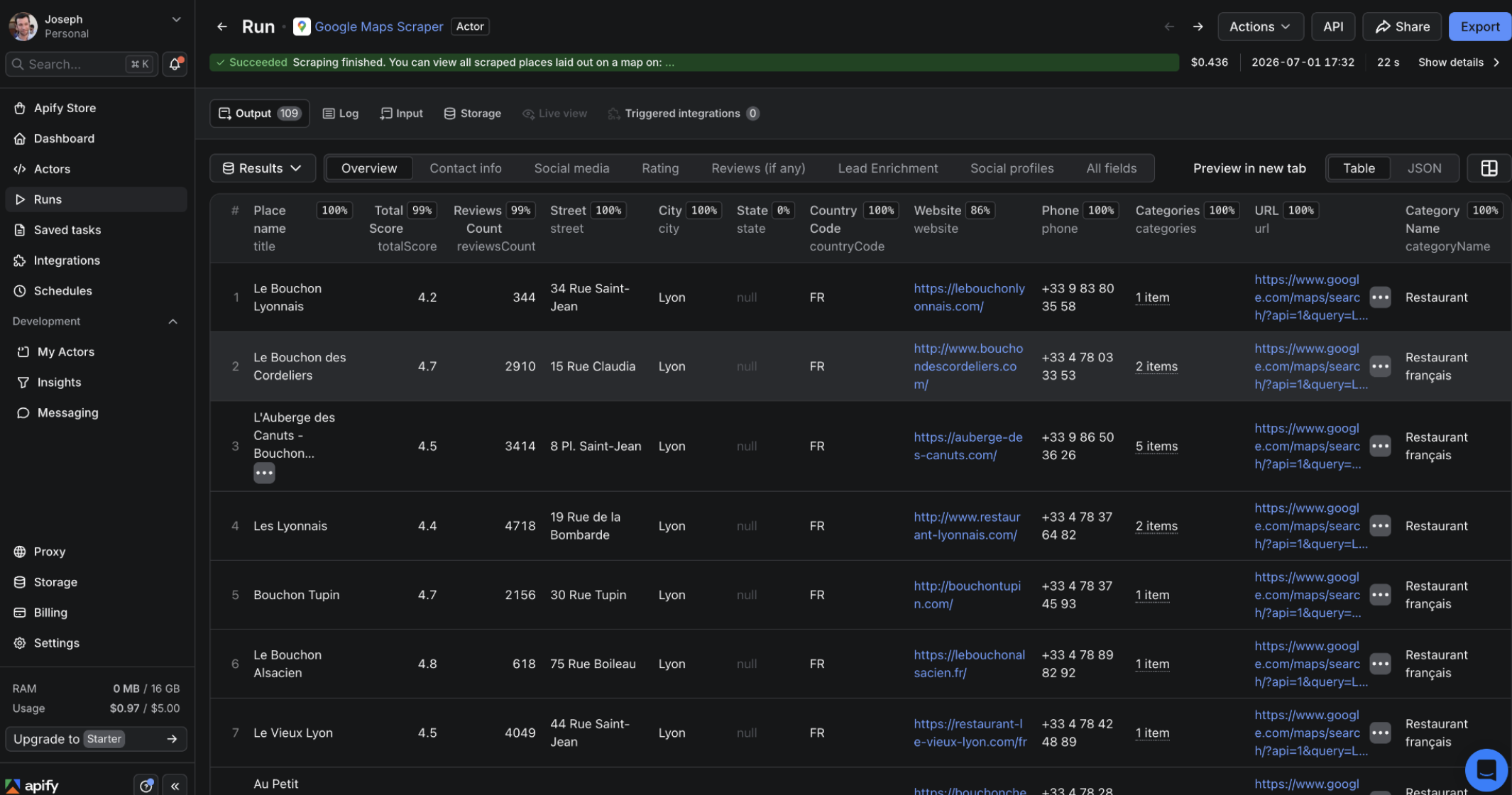
À la deuxième place de notre classement, on retrouve Apify. Niveau rapidité, rien à redire : il passe sous la barre de notre gagnant en bouclant le travail en 12 petites secondes. C’est vif. De plus le nombre de paramétres (paramétres géographiques, enrichissement de contacts, coûts capés par run de scraping) est extrêmement complet.
Là où le bât blesse, c'est sur la quantité dans l'assiette : l'outil a calé en route en ne nous rapportant que 109 résultats sur les 120 bouchons lyonnais attendus. Pour la complétude, on repassera. Côté addition, après avoir lancé l'extraction, l'interface affichait une note de 0,436 $, ce qui nous fait grimper à 0,004 $ par lieu scrapé — soit presque quatre fois plus cher qu'Openscraper. On apprécie quand même le geste de la maison qui offre 5 $ de crédits gratuits chaque mois. En revanche, impossible de consommer à la carte en Pay-as-you-go : vous serez obligé de passer à la caisse avec un abonnement mensuel fixe :
On appréciera :
• Un scraping très rapide ⚡
• Très paramétrable
On aime moins :
• Des trous dans la requête (données incomplètes)
3. Hasdata :
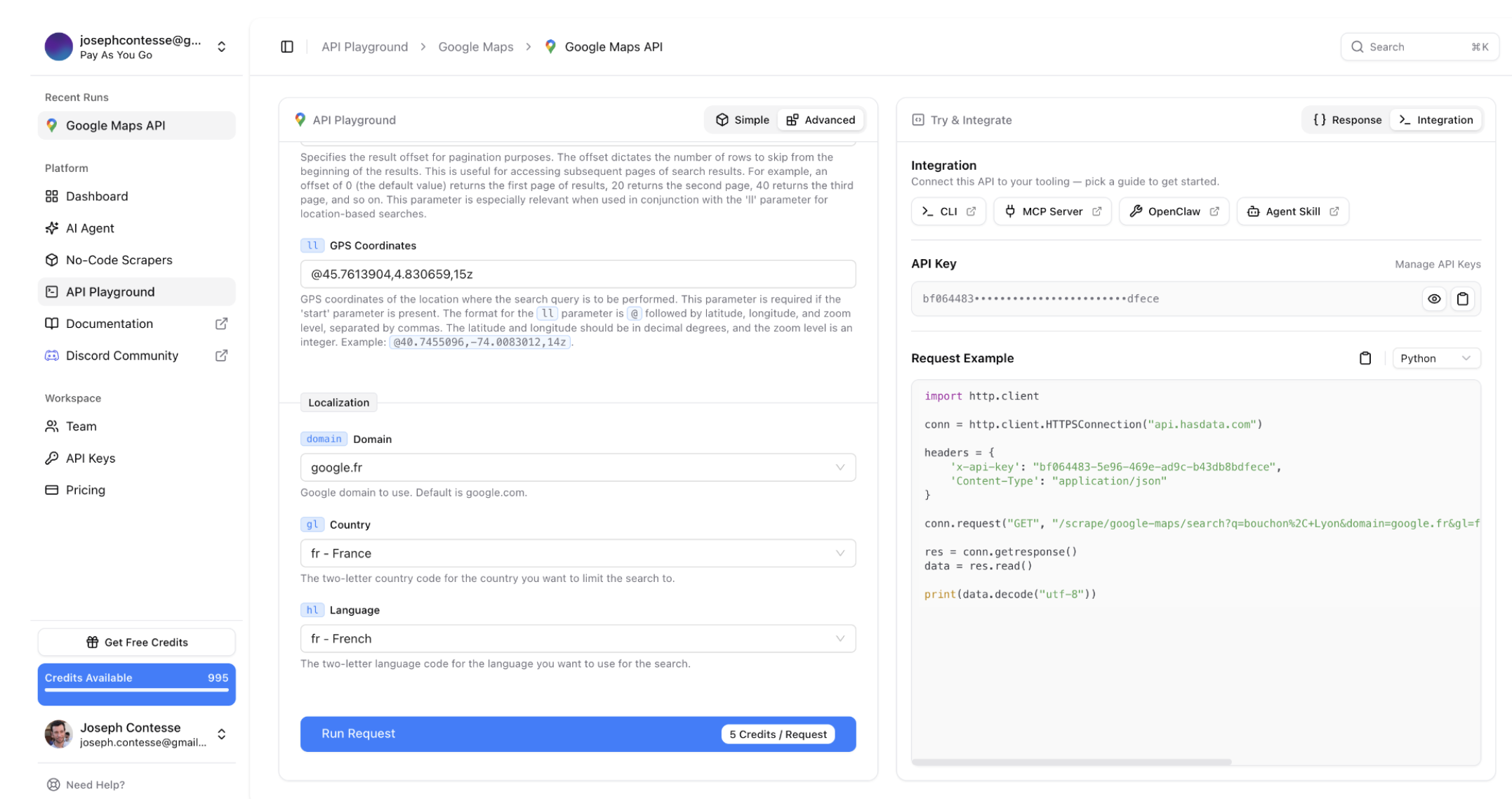
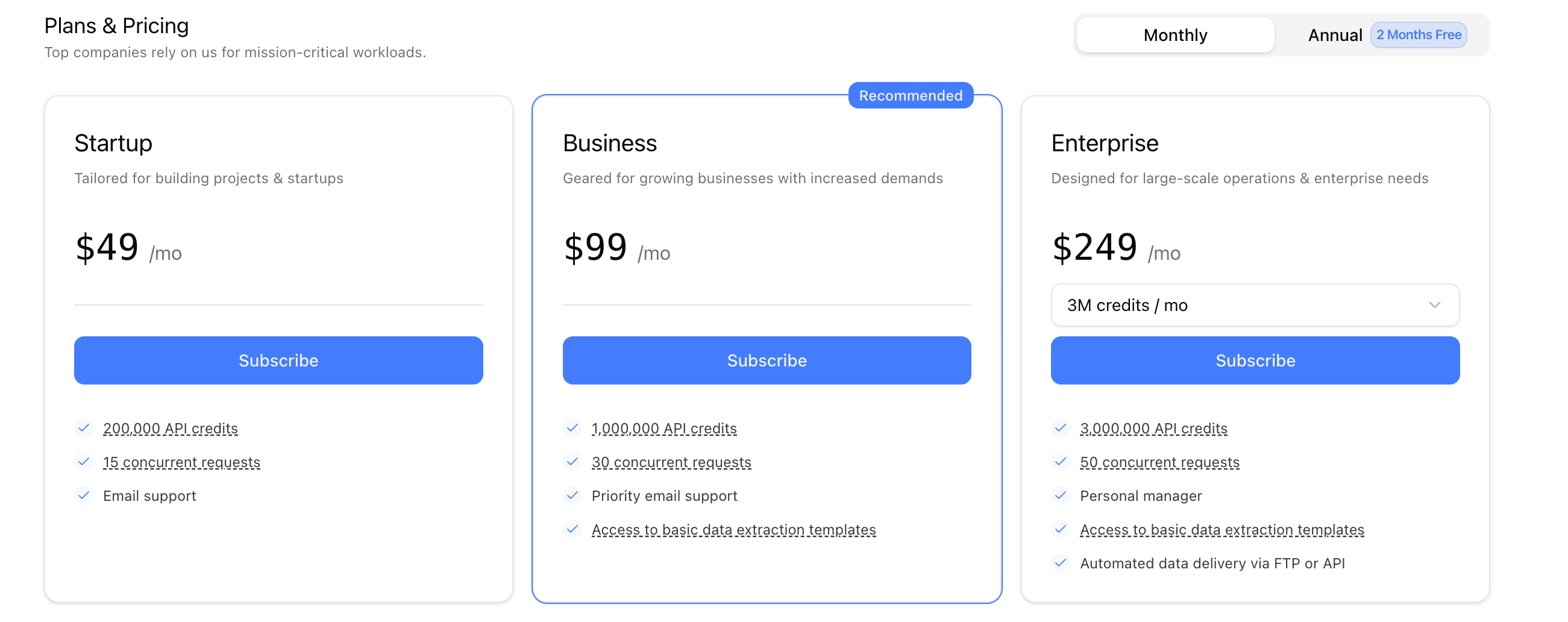
Sur la troisième marche du podium, on retrouve Hasdata. Pour le coup, pas de jaloux sur la quantité : le scraper a ramené 127 résultats dans ses filets. Après un petit nettoyage des données, on a débusqué deux doublons, ce qui nous ramène exactement à un total réel de 125 établissements, soit un sans-faute identique à celui d'Openscraper en termes de complétude. En revanche, l'outil se montre un peu moins compétitif sur le reste. Côté chrono, il lui faut 29,22 secondes pour faire le tour de la question, ce qui reste tout à fait honorable mais plus lent que le peloton de tête. C'est surtout au moment de passer à la caisse que l'expérience se corse : à 0,0098 $ par ligne, le tarif grimpe nettement. De plus, la plateforme ne propose pas d'option en Pay-as-you-go, ce qui vous obligera à souscrire à un forfait mensuel fixe même pour des besoins ponctuels. Les forfaits en question :
Comme Openscraper on a besoin de coder pour l’utiliser correctement sur Google Maps en se connectant à leur API. Leur plateforme SaaS seule ne permettant pas de récupérer des résultats au delà du 20ème résultat par url.
Voici un code pour extraire les résultats en formats Excel (remplacez bien "YOUR_API_KEY" par votre clé API 😉) :
On appréciera :
• Les données récoltées sont complètes ✅
On aime moins :
• Le prix 💳💥
4. Phantombuster :
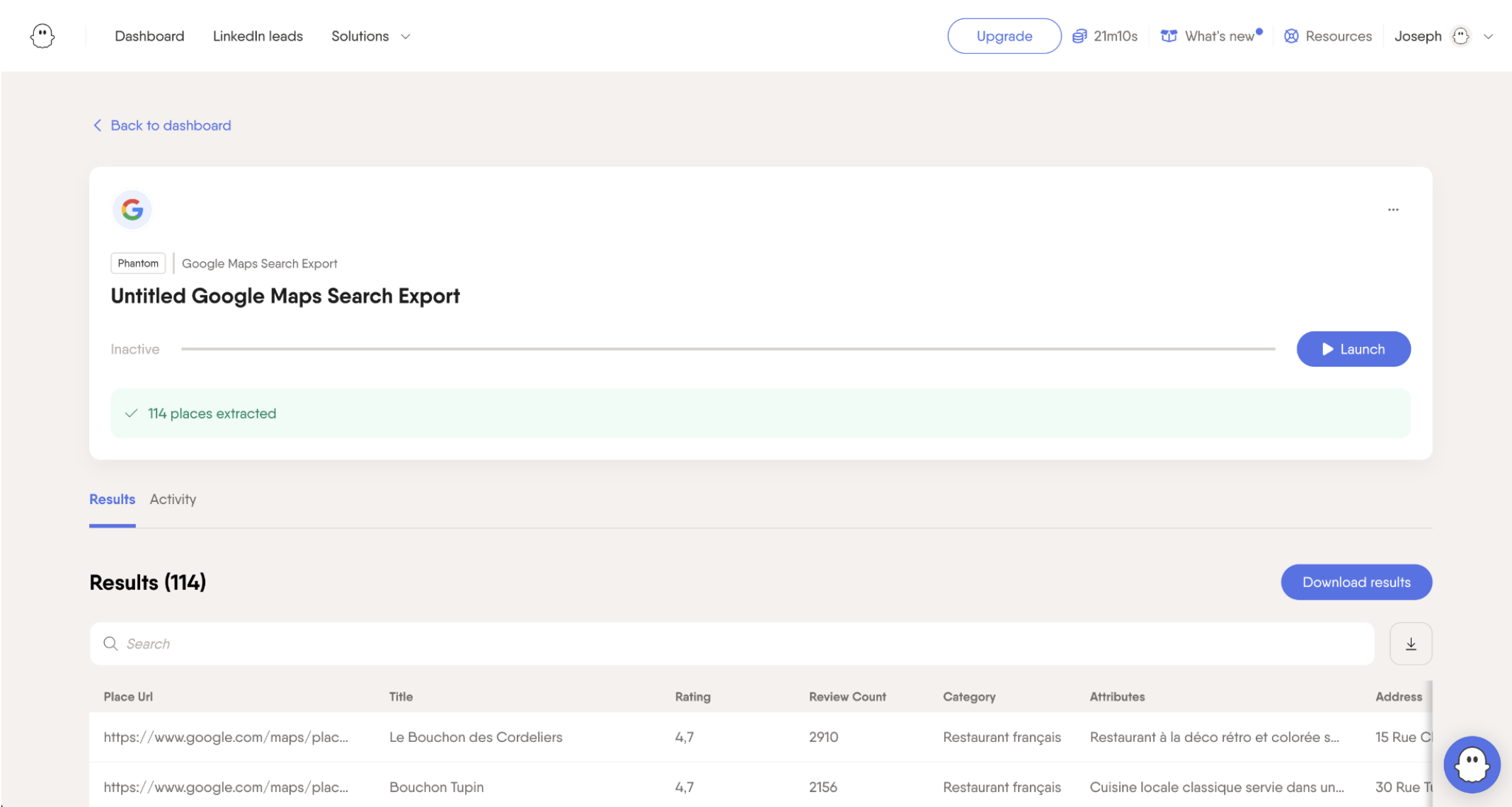
La plateforme de Phantombuster est très facile d’utilisation ce qui est parfait quand on est en proie aux terribles pics glycémiques liés à la digestion après la fréquentation d’un Bouchon Lyonnais. Il n’y a pas sur Phantombuster de décompte des crédits mais un décompte du temps de scraping utilisé par leurs scrapers.
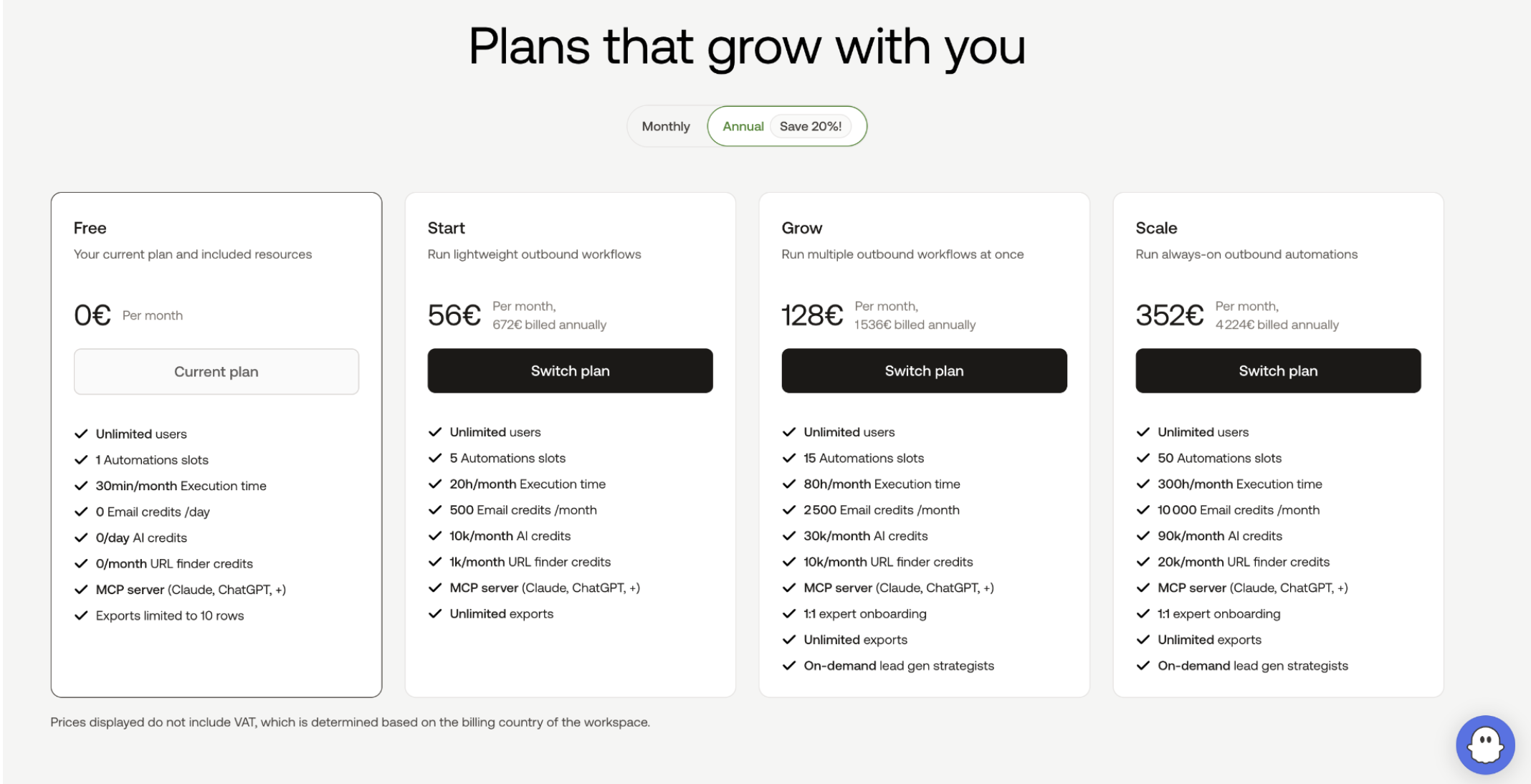
Pour télécharger les données vous devez opter au minimum pour leur offre Start à 56 euros par mois et vous avez le droit à 20h d'exécution. Ce qui n’est pas tant que ça vu la lenteur de leurs produits 😥 Il nous a fallu 11 minutes pour scraper tous les lieux de notre url. Phantombuster en a trouvé 114 (ce qui n'est pas tout à fait complet). Au prorata des 20h pour 56 € cela nous donne 0,0047€ par résultat (0,0053$).
Voici leurs abonnements :
On appréciera :
• La simplicité d'utilisation ✨
On aime moins :
• La terrible lenteur (est-elle vraiement nécessaire ?)
5. Outscraper :

Outscraper est souvent bien classé dans les différents comparatifs trouvables sur internet. Avec un prix de 0.003$ / lieu dans leur plus petite formule, nous avons affaire au deuxième scraper le moins cher du marché derrière Openscraper. Néanmoins deux gros bémols apparaissent :
1. La complétude des données. Étonnamment dans nos différents essais, sur les plus de 120 lieux normalement récupérables, il n’y en a jamais eu plus de 51 dans les résultats. Espérons que ce bug qui apparaissait sur notre url de test sera rapidement corrigé.
2. Le temps de fonctionnement, toujours supérieur à 30 minutes sur nos différents tests
On appréciera :
• Le prix
On aime moins :
• Uniquement la moitié des restaurants récupérés
• Temps de fonctionnement très lent
Conclusion : Quel scraper Google Maps choisir pour vos projets ?
Ce crash-test au cœur des bouchons lyonnais met en lumière une réalité évidente : tous les scrapers Google Maps ne se valent pas. Nous avons beau avoir tester des plateformes qui se trouvent parmi les plus performantes du marché, on observe quand même de gros écarts dans les prix, la vitesse d'exécution et la complétude des données.
- Côté budget et efficacité : OpenScraper.ai s'impose comme le grand gagnant de ce comparatif en offrant un ratio prix/vitesse imbattable (0,00112 $ par ligne en seulement 17,5 secondes), suivi de près par Apify sur le plan de la rapidité pure (12 secondes chrono), bien que ce dernier s'avère plus onéreux et nécessite un abonnement fixe.
- Côté complétude : Si OpenScraper.ai et Hasdata réussissent un sans-faute en extrayant l'intégralité des 125 résultats attendus, d'autres acteurs pourtant populaires montrent de sérieuses limites. Outscraper n'a ainsi récupéré qu'à peine la moitié des établissements lors de nos tests, tandis que Phantombuster et Apify ont laissé plusieurs adresses en route.
- Côté rapidité : La fracture est également immense entre les solutions "API-first" ultra-véloces (sous la barre des 30 secondes pour le trio de tête) et les plateformes plus visuelles comme Phantombuster ou Outscraper, qui demandent de longues minutes (voire plus d'une demi-heure) pour traiter une simple requête géographique.